






PAM仅需初始/目标手部姿态与物体几何信息,即可生成高保真交互视频。
Project Page:https://link.zhihu.com/?target=https%3A//gasaiyu.github.io/PAM.github.io/
01 TL;DR
▪ 在只给定初始姿态、目标姿态和不含外观的物体几何信息的输入下,如何直接生成逼真的手物交互(HOI)视频?
▪ 现有方法存在一系列问题:姿态合成方法只能预测 MANO 轨迹,而不能生成像素细节;文生图方法能生成能产生外观,但缺乏动态信息;而视频生成方法目前大多依赖完整的姿态序列和首帧作为输入,导致其无法真正应用于 Sim-to-Real数据生成管线。
▪ 我们提出PAM (Pose-Appearance-Motion),一个统一的数据生成引擎,利用姿态、外观和运动的解耦生成过程,完美解决上述痛点。
▪ 这是第一个仅需条件初始姿态、目标姿态和物体的几何信息作为输入,即可实现高质量 Sim-to-Real 手物交互视频生成的框架,且利用这个管线合成的数据能显著提升下游任务(例如手部姿态估计)的性能。
02 简介
手物交互(HOI)的重建与合成正逐渐成为具身智能和 AR/VR 领域的核心基石。尽管数据驱动范式推动了准确的手部姿态估计和视频生成领域的的快速发展,但获取带有详细标注的真实 HOI序列需要耗费极大的人力物力,这严重限制了可扩展性。
为了打破这一数据壁垒,北京大学联合清华大学、智源研究院(BAAI)、上海交通大学及东方理工大学提出了一个突破性的统一引擎——PAM。PAM 能够将姿态(Pose)、外观(Appearance)和运动(Motion)无缝整合到一个连贯的框架中。用户只需提供初始和目标姿态以及物体几何形状,PAM 就能生成具有连贯动态和逼真手物交互的视频。实验证明,PAM 不仅在视频保真度和几何准确度上大幅超越现有方法,其生成的合成视频还能直接作为数据增强工具,使下游手部姿态估计模型在仅使用 50%真实数据加上合成数据的情况下,就能匹配使用100%真实数据的效果!
03研究动机
随着深度学习和扩散模型的出现,大规模生成 HOI 视频展现出了巨大潜力。然而,纵观当前最先进的方法,整个研究领域呈现出三种趋势:
1.纯姿态合成(Pose-only synthesis):只预测手部MANO轨迹而不生成外观,缺乏视觉真实感,降低了其实用价值。
2.单图外观生成(Appearance generation):根据掩码或 2D 提示生成外观,但完全无法捕捉时间上的动态连贯性。
3.视频运动生成(Motion generation):虽然能生成视频,但需要完整的姿态序列和真实的视频第一帧作为输入,这些条件在实际场景中较难获得,容易获得的是模拟器中的手部姿态数据,但由于模拟器中根本无法获取真实的第一帧,这类方法不适合 Sim-to-Real的部署。
基于上述痛点,研究团队认为 HOI 生成亟需一个能统一融合姿态、外观和运动的引擎。因此,PAM 引入了整合运动与外观的扩散过程,绕过了对第一帧条件和完成手部姿态序列的依赖,从而最大化了运动和外观的多样性。
04 PAM 方法
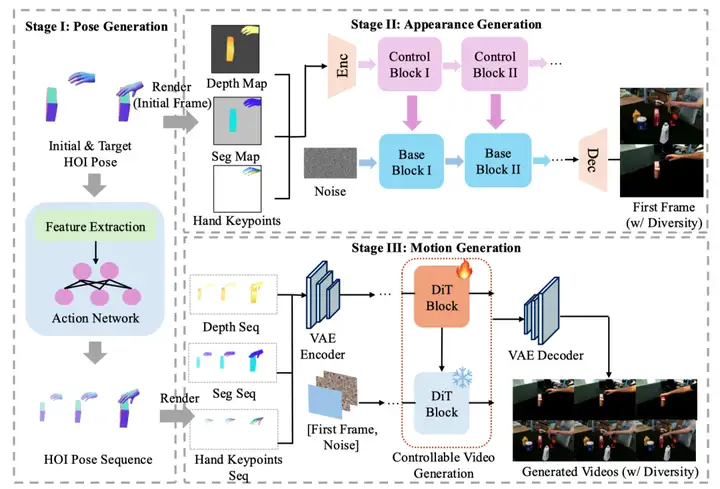
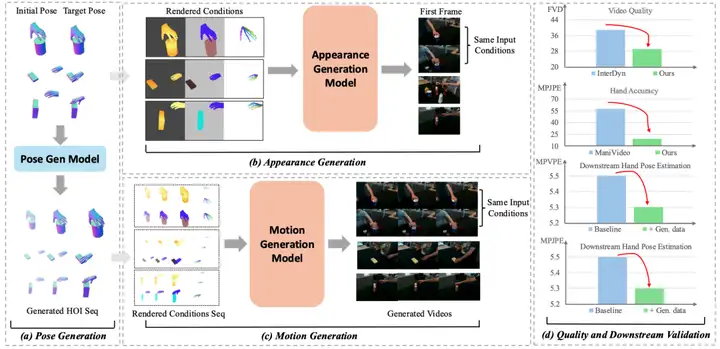
方法概览
给定初始 MANO 手部姿态 、无外观的物体 Mesh 、初始 6-DoF 物体姿态 以及目标手部 MANO 姿态 ,PAM 的目标是生成一段逼真的 HOI 视频。整个模型可以形式化为一个生成函数 :
该模型最终输出一段连贯且具有物理约束的 RGB 视频帧序列 。为了应对生成 HOI 视频的高维时空流形的复杂性,PAM 将生成过程解构为三个核心阶段:
第一阶段:姿态生成 (Pose Generation)
在这个阶段,模型主要解决中间物理运动的插值问题。使用预训练的姿态生成模型(如 GraspXL)来合成对齐的手物交互姿态序列。模型接收 作为输入,输出时间上连贯的手部和物体运动轨迹 。这确保了物理一致性,为后续的视觉渲染奠定几何基础。
第二阶段:外观生成 (Appearance Generation)
为了解决从模拟器到真实视频的视觉鸿沟,PAM 利用可控的图像扩散模型 Flux 来合成逼真的视频第一帧 。单靠深度图和语义掩码不足以处理手部的高自由度。模型将以下三种条件融合并作为生成引导,它们均为 的特征图:
▪ 深度图 (Depth Maps) :保证全局的几何连贯性。
▪ 语义掩码 (Semantic Masks) :保证实例级别的语义一致性。
▪ 手部关键点映射 (Hand Keypoints) :提供精确的手部骨骼拓扑结构,保证手部细节生成的一致性。
这些条件首先通过 VAE 编码为 的潜在表示,在通道维度上拼接后,注入到 ControlNet 分支的 DiT 块中。特征的注入计算公式如下:
其中 是原始 Flux 模型中第 7 层 DiT 块的输出, 是接收拼接条件输入的复制 DiT 块的输出,而零卷积层 (Zero-convolution layer) 为参数全零初始化的 卷积层。
第三阶段:运动生成 (Motion Generation)
在生成首帧 后,模型将第一阶段生成的序列 逐帧渲染,得到对应的深度图、语义图和关键点序列。随后,利用预训练的视频 VAE 将这些空间条件编码为形状为 的潜在张量。
PAM 采用基于 CogVideoX 的可控视频扩散模型来生成最终的视频流。为了保持与姿态序列的一致性,视频模型沿用了上述公式的特征融合机制,将多模态特征通过 12 个复制的 DiT 块注入网络。特别地,在训练阶段,为了防止模型过度依赖某单一模态特征,每种条件都会以 的概率被随机掩码,从而提升模型的泛化能力。
05实验结果
基准测试
团队在 DexYCB(聚焦于单手交互)和 OAKINK2(聚焦于双手复杂交互)两个基准数据集上对 PAM 进行了全面评估,并与当前最先进的 ManiVideo、InterDyn 和 CosHand 等方法进行了对比。
定量结果
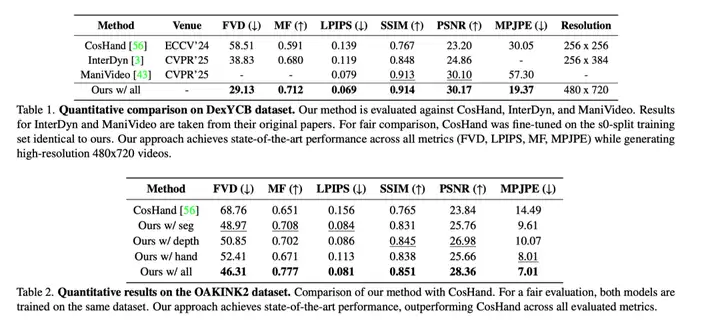
▪ 在 DexYCB 数据集上:PAM 实现了 29.13 的 FVD(Fréchet Video Distance,反映视频整体的时空连贯性与真实度,该数值越低越好),大幅优于 InterDyn 的 38.83。在反映手部姿态准确度的 MPJPE 指标上,PAM 达到了19.37 mm,远优于 CosHand 的 30.05 mm。此外,在结构相似性(SSIM)和运动保真度(MF)等指标上,PAM 也稳居第一。
▪ 在 OAKINK2 数据集上:面对更复杂的双手交互场景,PAM 同样展现出强大的建模能力,将 FVD 从 CosHand 的 68.76 显著降至 46.31,MPJPE 从 14.49 mm 大幅降低至 7.01 mm。
▪ 更高清的分辨率:相比于基线方法生成的256 \times 256 (CosHand) 或 256 \times 384 (InterDyn) 模糊视频,PAM 能够稳定生成 480 \times 720的高保真、高分辨率交互视频。
定性结果

▪ 如上图所示,现有方法(如 CosHand)由于仅依赖手部掩码作为单一条件,缺乏深度的几何引导,且缺少显式的时间建模机制,导致生成的视频往往出现手部姿态畸变以及严重的帧间闪烁。相比之下,PAM 利用带有时间注意力机制的视频扩散基础模型,加以多条件的控制,保证了较强的帧间连贯性。
06 多条件的消融实验

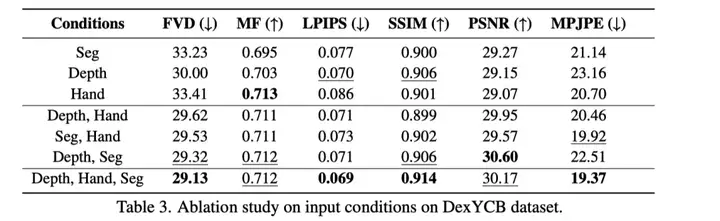
▪ DexYCB数据集上的消融实验证实,PAM 的“深度图+语义掩码+手部关键点”多模态控制组合缺一不可。如上图所示,仅靠手部关键点会导致整体外观质量下降,而仅靠语义掩码或深度图则会引发手部姿态的错位失真。PAM 巧妙结合了全局场景理解(深度与语义)与局部手部细节(关键点),明确保留了手部结构的细节。这使得 PAM 不仅在背景和前景的生成上具备更高的视觉保真度,还成功消除了几何错位,生成了准确、流畅且符合物理常理的视频序列。
07 Sim-To-Real生成

如上图所示,PAM 展现了强大的 Sim-to-Real 迁移能力。仅仅给定初始和终止状态的HOI Pose,利用解耦架构,模型成功结合了 GraspXL 的运动先验与扩散模型的外观建模,合成了具有不同主体和背景的多样化、逼真的视频。这些视频为之后的下游任务提供了源源不断的数据生成管线。
08 下游任务验证
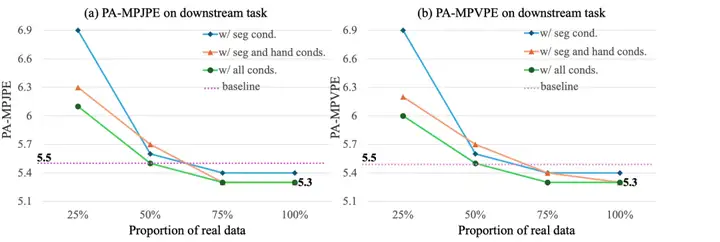
为了评估生成视频的实用性,研究人员将合成视频用于下游手部姿态估计任务(SimpleHand 模型)的数据增强。PAM 训练生成了 3,400 个视频序列(包含 207,400 帧)作为增强数据。
结果表明,使用合成数据结合不同比例的真实数据进行训练,始终能提高手部姿态估计的准确度。从上图中可以看到,仅使用 50% 真实数据加上 PAM 生成的合成样本,其性能就足以具备与使用 100% 真实数据基线相竞争的实力!这证明了合成数据能有效弥补真实数据量的不足。
09 总结
PAM 提出了一个创新的 Pose-Appearance-Motion 解耦架构,成功打破了传统方法依赖真实第一帧的瓶颈,实现了从极简姿态输入到高保真 HOI 视频的生成。其卓越的感知质量、几何准确度以及对下游任务的显著增益,为具身智能领域的生成模型研究提供了坚实的基础
