





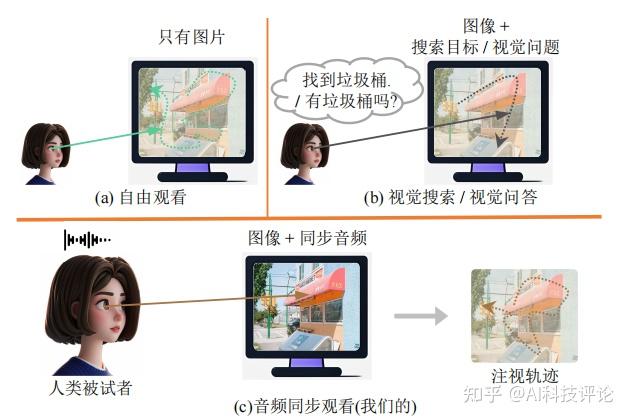
你有没有想过,当我们看到一幅图画并听到相关的描述时,我们的眼睛是如何“自动”跟随声音去寻找画面中的对应物?这看似自然的动作,其背后却隐藏着一套极其复杂的生理与心理机制。而今天,人工智能已经能够在一定程度上模拟这种能力了!
近日,中国人民大学高瓴人工智能学院

在计算机视觉与人工智能领域,模拟和预测人类的注视轨迹一直是一个至关重要的研究方向。近年来,随着虚拟角色和智能人机交互的快速发展,如何通过更自然的方式让虚拟人物模仿人类的眼动行为成为了热门话题。然而,大多数注视轨迹预测任务主要集中于视觉信息,尽管这些研究为理解人类视觉系统提供了宝贵的洞见,但它们并未充分考虑音频刺激对人类注视行为的影响。
为填补这一空白,团队提出了一个全新的任务——Audio Synchronized Viewing:旨在预测人类在听到音频信号的同时,在图像中的注视轨迹。
一、任务的形式化描述
任务的输入包括一张图像 和一段音频 。使用语音识别工具,可以得到音频中的词语及其在音频中的开始和结束时间:
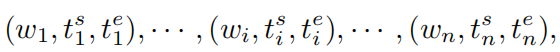
在此任务中,人类的注视与音频时间戳保持一致。人们倾向于注视某个点,直到听到下一个单词。因此,任务旨在预测每个结束时间的注视点。对于一个图像-音频对 - ,有 条人类注视轨迹:
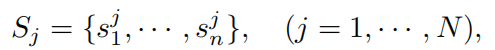
任务的目标是预测一条注视轨迹,使其尽可能地接近人类的注视轨迹。
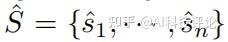
二、方法
为了解决这一新的任务,团队将眼球看作一种弹簧系统,提出了基于物理启发的动力系统的全新学习框架 EyEar (Eye moving while Ear listening)。该框架通过考虑眼球固有运动趋势、视觉显著吸引力以及音频的语义吸引力三大关键因素来预测注视点。此外,团队提出了一个基于概率密度的评分方法,以克服注视轨迹的高度个体差异性,从而提升优化的稳定性和评估的可靠性。
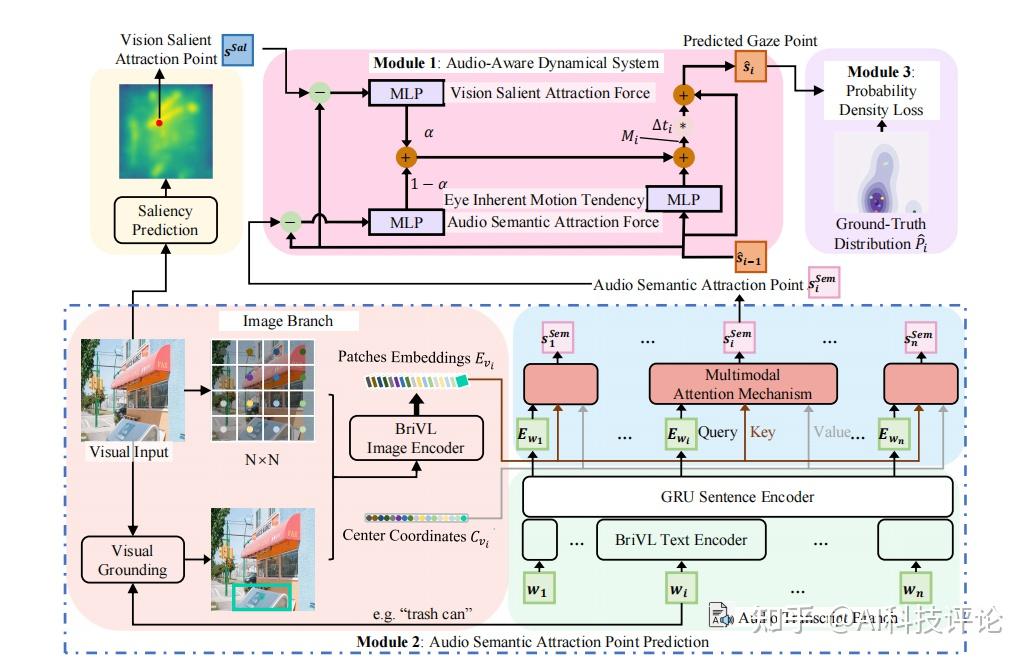
- 创新的物理启发的动力系统:
为了捕捉眼睛的运动特征,团队提出了一种受物理学启发的音频感知动力系统。在动力系统中,存在一种被称为状态的概念,其由一组可确定的实数表示。状态的微小变化对应于这些实数的微小变化。动力系统的演化由一组函数决定,这些函数描述了未来状态如何依赖于当前状态。在这个任务中,状态指代注视位置。以下是动力系统的数学公式(参见模块1):
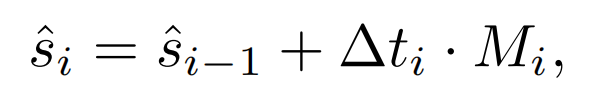
其中,当前预测的注视点根据前一个注视点,时间间隔,以及运动向量计算得到。具体而言,运动向量的计算公式如下:

团队综合考虑了影响运动向量的三个力的来源。上述公式中的神经网络(MLP)对应于动力系统中的一组函数(由三种力引起的运动分量)。式中的第一项表示由保持在前一个注视点的固有运动趋势的力引起的运动分量,它与任何刺激无关。第二项表示由吸引注视点到图像中最显著的点的力引起的运动分量。
考虑这种力是因为人类的注意力有时可能完全被图像的显著部分所吸引。第三项表示由吸引注视点到音频语义吸引点的力引起的运动分量。这一项考虑了人类在音频刺激下的注意力。直观上,当人类听到一些词语时,他们会关注与之语义相关的部分。
最后,可学习的权重参数α衡量人类注意力被不同部分吸引的程度。
2.音频语义吸引点预测:
为了衡量图像区域和听到的词语之间的广泛语义关系并得到准确的音频语义吸引点,团队精心设计了图像分支、音频转录分支以及多模态注意力机制,用于整合不同类型的信息并预测下一个音频语义吸引点。
3.概率密度评分方法:
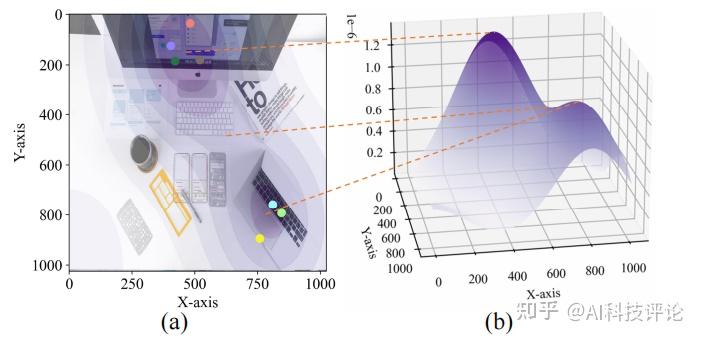
由于人的真实注视轨迹具有高度个体差异,模型的优化和评估面临挑战。如图所示,当听到“电脑”时,受试者的注视点集中在电脑上。然而,由于图像中有两台电脑,注视点被分成了两个组。这样的多样化目标使得常用的均方误差(MSE)损失容易受到混淆。在该示例中,两个组之间的中间点会最小化MSE损失,但这并不是我们想要的,因为该点并不对应任何一台电脑。为此,团队提出了一种基于分布的度量方法,称为概率密度评分(PDS),以替代基于点的度量(如欧几里得距离)。首先,通过高斯核密度估计对多个真实注视点形成的分布进行估计,并将其作为真实分布。其次,对于预测的注视点:
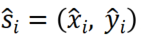
通过其在该分布上的概率密度的归一化值来衡量其与真实分布的契合程度:
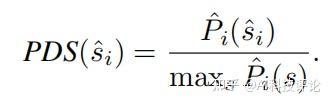
三、数据集与实验
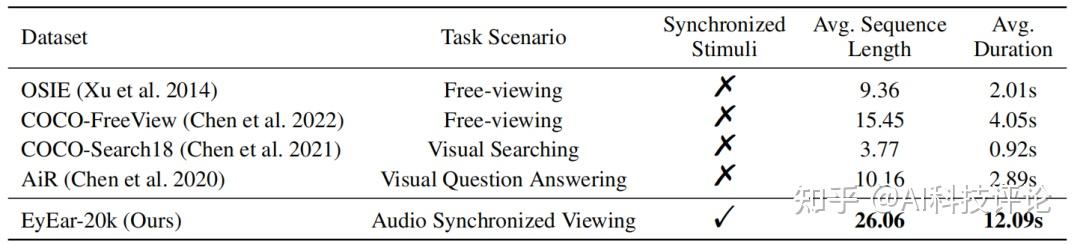
为支持EyEar框架的开发,研究团队收集了一个包含20,000个注视点的数据集。该数据集收集自8个受试者,在他们听取与图像内容相关的音频描述时,通过眼动追踪设备记录下他们的注视轨迹。与现有的数据集相比,这一数据集不仅具有更长的注视序列和持续时间,还能更好地模拟人类在自然环境中的注视行为。
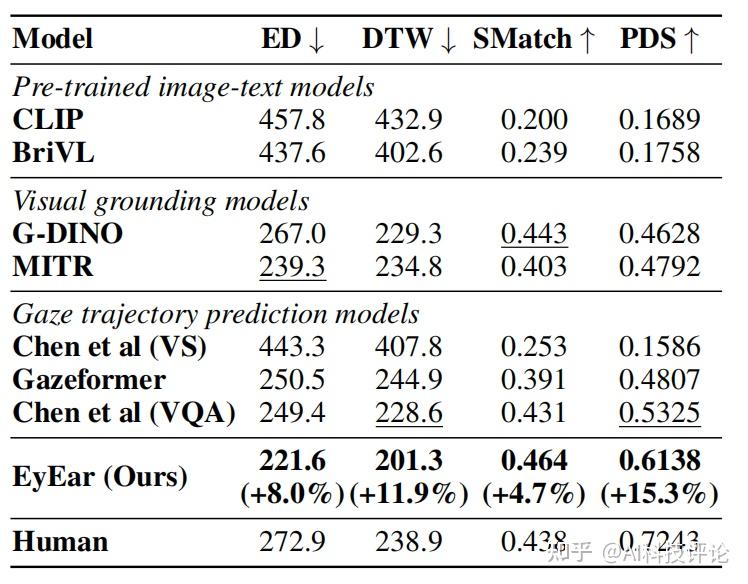
通过对比现有的多个基线模型(包括预训练的图文对齐模型、视觉定位模型和注视轨迹预测模型),EyEar框架在所有评估指标上均取得了显著的性能提升。尤其是在PDS(概率密度评分)指标上,EyEar的表现比最好的基线模型高出15%。
EyEar不仅能够准确预测注视轨迹,还能模仿人类眼动的自然运动模式,特别是在音频语义的引导下,眼动行为表现得尤为自然。尽管与人类的真实眼动相比,EyEar仍有一定差距,但其在多模态注视轨迹预测任务中的优势是显而易见的。

四、未来展望
未来,研究团队计划将EyEar框架扩展到视频场景,以进一步模拟真实世界中的视觉与听觉互动。此外,他们还将尝试将开放的音频刺激应用于该框架,探索更多样化的听觉信息对注视行为的影响。
